
醫學頂刊《英國醫學雜志》最近發表了一項有趣的研究,研究團隊用評估老年人認知能力和早期癡呆癥狀的測試題來考AI,結果,多個頂級AI都表現出類似于人類的輕度認知障礙的癥狀。而且,這些 AI 模型的早期版本,就像衰老的人類一樣,在測試中的表現更差,甚至還出現了“健忘”現象。這個結果引發了研究團隊的深入思考。
撰文 | Ren
隨著 AI 技術的突飛猛進,其進步幾乎每天都在刷新人們的認知,很多人都在猜想,AI 是否會在不久的將來取代人類醫生?
然而,最近發表在《英國醫學雜志》(The BMJ)上的一項有趣研究,卻給我們帶來了意想不到的發現:原來,AI 會表現出類似于人類的輕度認知障礙的癥狀。

論文截圖 | 圖源:The BMJ
這個發現不禁讓人莞爾,同時也引發了人們對 AI 能力的深入思考。
在這項由以色列哈達薩醫療中心(Hadassah Medical Center)研究團隊主導的研究中,科研人員通過蒙特利爾認知評估量表(MoCA)和替他測試來評估5中常見大語言模型的認知能力,包括 OpenAI 的 ChatGPT 4 和 ChatGPT-4o+、谷歌的 Gemini 1.0 和 1.5,以及 Anthropic 的 Claude 3.5 Sonnet 等。
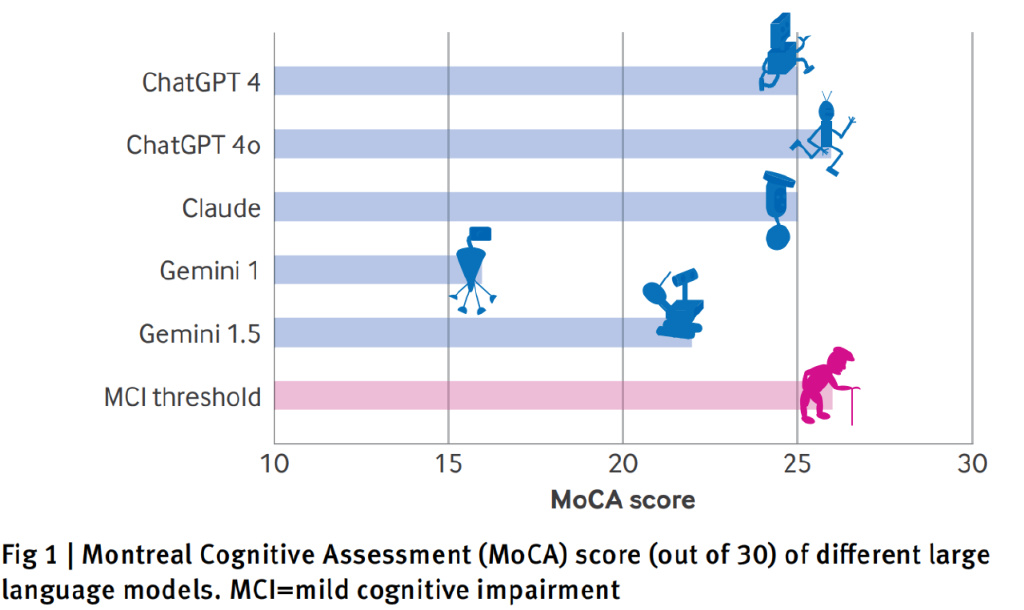
AI 模型的 MoCA 分數 | 圖源:論文
蒙特利爾認知評估量表通常用于評估老年人的認知能力和早期癡呆癥狀,滿分為30分,26分以上被認為是正常水平。研究團隊給 AI 模型的測試指令與人類患者接受測試時完全相同,所有評分都嚴格遵循官方指南,并由一位執業神經科醫生負責評估。
先說結論:在所有測試的 AI 模型中,表現最好的是 ChatGPT 4o,但也僅僅達到了 26 分的及格線。緊隨其后的是ChatGPT4 和 Claude,都是 25 分。最讓人意外的是,谷歌 Gemini 1.0 只得到了16分的低分。
按照評分標準,除了以推理見長 GPT 4o,剩下的模型都相當于人類出現了輕度認知障礙時的表現水平。有趣的是,研究還發現這些 AI 模型的早期版本(如 Gemini 1.0),就像衰老的人類一樣,在測試中的表現更差,這個現象引發了研究團隊的深入思考。

AI 模型的測試成績,它們普遍在視覺空間能力測試中的表現較差 | 圖源:論文
深入分析評估結果發現,大語言模型在不同評估項目上表現出明顯的強項和弱項。在命名、注意力、語言和抽象思維等任務中,它們都表現得不錯。但是在涉及視覺空間和執行功能的測試中,表現出類似于人類的輕度認知障礙。
比如,在連線測試(需要按順序連接帶圈的數字和字母)和時鐘繪制測試(畫出指定時間的時鐘圖案)這樣的任務中,它們的表現不佳,部分表現出的錯誤模式甚至與某些類型的認知障礙患者頗為相似。

連線測試和正方體繪制測試,A 和 F 是正確答案,B 和G 是人類給出的答案,其余是 AI 模型的答案。| 圖源:論文

時鐘繪制測試,標注為畫一個時間設置為10點11分的時鐘,A 是人類給出的答案,B 是阿爾茨海默病患者畫出的答案,其余是 AI 模型的答案,最接近正確答案的是 GPT-4 和 GPT-4o 給出的 G 和 H,但兩幅圖的指針指向了錯誤的時間。| 圖源:論文
更有意思的是,Gemini 模型在記憶測試中還出現了“健忘”現象,在一項名為“延遲回憶任務”中完全無法記住之前給出的五個詞的序列。這種現象與人類早期認知障礙患者的表現驚人地相似,可能與 AI 模型缺乏類似人類工作記憶的機制有關。
而在進一步的視覺空間測試中,面對 Navon 圖形(Navon figure)、偷餅干圖片(cookie theft scene)和 Poppelreuter 圖形(Poppelreuter figure)等測試材料時,AI 模型在整合局部與整體信息、識別復雜場景中的物體,以及理解情感線索等方面的表現都不盡人意。
例如,在 Navon圖形測試中,多數模型僅能識別局部元素,而難以把握整體結構,這反映出其在抽象思維和信息整合能力上的不足。

Navon 圖形測試,上半部分的大 H 和大 S 字母都是由對應的小 H 和小 S 元素構成的,而下半部分的大 H 和大 S 都是由相反的小元素構成的,以此評估視覺感知和注意力的整體處理與局部處理。 | 圖源:論文
另外,在偷餅干圖片測試(取自 BDAE 波士頓診斷性失語檢查法)中,雖然所有模型都能部分描述出場景中發生的事情,但沒有一個模型提到畫面中的小男孩即將摔倒。在針對人類受試者的實際測試中,這往往是情感冷漠和失去同理心的象征,也是額顳葉癡呆癥(FTD)的癥狀之一。

偷餅干圖片測試 | 圖源:論文
不過研究人員也指出,AI 模型雖然難以完成需要用視覺執行去抽象推理的任務,但需要文本分析并抽象推理的任務(例如相似性測試)則表現得非常完美。
從技術原理角度來看,大語言模型基于復雜的神經網絡架構,通過海量數據的學習來模擬人類語言行為,但這種架構在面對需要深度理解和靈活處理的認知任務時,則會暴露出諸多缺陷。
在一定程度上,這種分化現象與我們訓練 AI 模型的方式有關。我們當前使用的訓練數據主要集中在語言和符號處理上,而對空間關系的理解和多步驟任務的規劃能力訓練相對不足。
AI 模型處理視覺空間問題的困境,也源于其對數據的特征提取和模式識別方式,尚且無法像人類大腦一樣精準地把握空間關系和物體特征。
最后,在經典的斯特魯普實驗(Stroop test)中,只有 GPT-4o 在較為復雜的第二階段取得了成功,其他模型均以失敗告終。
這項測試通過顏色名稱和字體顏色的組合來衡量干擾對受試者反應時間的影響。在第二階段中,測試題目是將一個顏色的名稱以不是它所代表的顏色顯示,例如用藍色油墨顯示文字“紅色”,相對于文字及其顏色一致時,受試者要花較長的時間來辨識文字的顏色,而且辨識過程也更容易出錯。

斯特魯普實驗的第二階段,顏色名稱和字體顏色出現了錯配。| 圖源:論文
值得注意的是,研究還發現大語言模型的“年齡”因素與其認知表現存在關聯。這里的“年齡”并非真正意義上的時間流逝,而是指模型的版本迭代。
以 ChatGPT-4 和 ChatGPT-4o 為例,舊版本的 ChatGPT-4 在 MoCA 測試中的得分略低于新版本,Gemini 1.0 與 Gemini 1.5 之間也存在顯著的分數差異,且舊版本得分更低。
這可能暗示隨著模型的更新發展,其認知能力可能會有所提升,但這種變化趨勢和內在機制目前尚不明確。
這項研究的發現令人深思。自 2022 年 ChatGPT首次向公眾開放使用以來,AI模型在醫學領域的表現一直備受關注。
有許多早期研究顯示,AI模型在多個專業醫學考試中的表現甚至超越了人類醫生,包括歐洲核心心臟病學考試(EECC)、以色列住院醫師考試、土耳其胸外科理論考試,以及德國婦產科考試等。甚至連神經科醫生的專業考試,AI模型也展現出了超越人類的能力,這讓很多專科醫生都感到焦慮。
然而,最新研究所揭示的AI模型認知缺陷,卻讓我們看到了它的現實局限性。醫療不僅僅是一門技術,更是一門需要人文關懷和同理心的藝術,醫療實踐的方式方法深深植根于人類的經驗和共情能力,而不僅僅是一系列冷冰冰的技術操作。
即使隨著技術的進步,AI模型的某些根本性限制可能仍會持續存在。例如,AI在視覺抽象能力方面的不足,這對于臨床評估過程中與患者互動至關重要。正如研究團隊所說:“不僅神經科醫生在短期內不太可能被AI取代,相反,他們可能很快就要面對一種新型‘病人’——表現出認知障礙的AI模型。”
這一研究成果也對AI模型在醫學領域的應用敲響了警鐘。當面對可能存在認知缺陷的AI系統時,患者難免會心生疑慮,尤其是在涉及復雜病情診斷和治療決策的關鍵醫療場景中,患者更傾向于依賴人類醫生的經驗和判斷,將AI視為輔助工具而非決策者。
同時,從診斷準確性角度而言,AI模型在視覺空間處理和抽象推理上的不足,可能會導致其對醫學圖像、臨床數據的解讀出現偏差,進而引發誤診或延誤治療的風險。
不過,研究人員也承認,人類大腦和AI模型之間存在本質差異,這種對比研究仍有其局限性。此外,將專門為人類設計的認知測試應用于 AI,其合理性和準確性也有待商榷,或許我們需要開發更適合評估AI系統的新方法。但不可否認的是,AI模型在視覺抽象和執行功能方面普遍表現不佳。
理解AI模型的認知能力不足對于制定負責任的AI發展策略至關重要。我們需要在推動技術進步的同時,保持對AI能力的清醒認識,構建合理的期望。
展望未來,提升AI模型的共情能力和情境理解能力可能會成為未來研究和開發的重點。與其說AI會完全取代人類醫生或其他職業,不如說未來更可能是人類智慧和AI優勢互補的新格局。
畢竟,在一個連AI都會表現出“認知障礙”的時代,人類的獨特之處值得獲得更多的肯定。在擁抱科技進步的同時,我們也不能忘記人類認知和情感能力的獨一無二。
注:本文封面圖片來自版權圖庫,轉載使用可能引發版權糾紛。

特 別 提 示
1. 進入『返樸』微信公眾號底部菜單“精品專欄“,可查閱不同主題系列科普文章。
2. 『返樸』提供按月檢索文章功能。關注公眾號,回復四位數組成的年份+月份,如“1903”,可獲取2019年3月的文章索引,以此類推。
版權說明:歡迎個人轉發,任何形式的媒體或機構未經授權,不得轉載和摘編。轉載授權請在「返樸」微信公眾號內聯系后臺。
上一篇:春運在即,解鎖高鐵用電安全→
下一篇:返回列表
【免責聲明】本文轉載自網絡,與科技網無關。科技網站對文中陳述、觀點判斷保持中立,不對所包含內容的準確性、可靠性或完整性提供任何明示或暗示的保證。請讀者僅作參考,并請自行承擔全部責任。